About
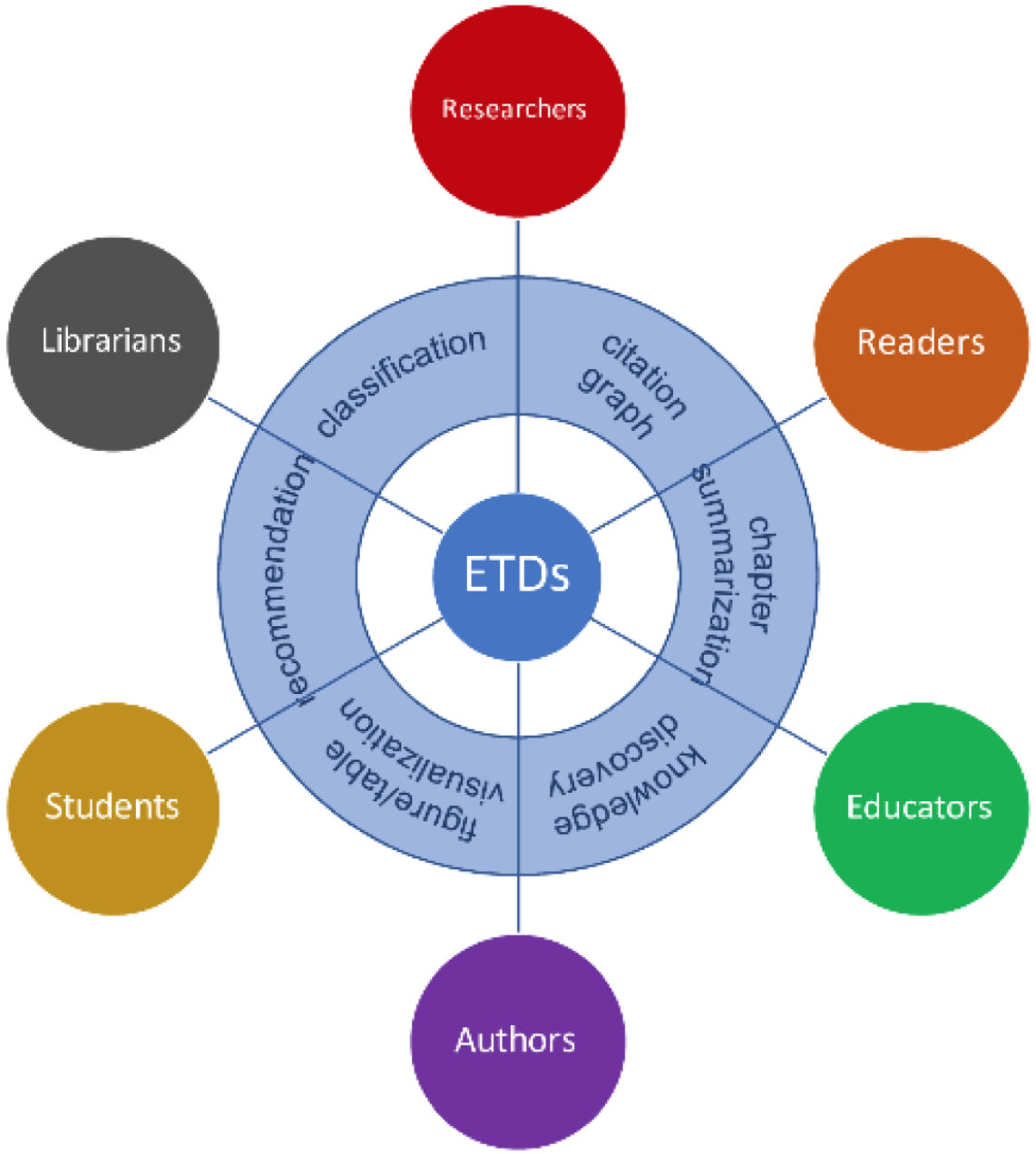
Virginia Tech University Libraries, in collaboration with Virginia Tech Department of Computer Science and Old Dominion University Department of Computer Science recieved grant from Institute of Museum and Library Services for conducting research in Mining Electronic Theses and Dissertations (ETDs). The project is motivated by the following library and community needs. (1) Despite huge volumes of book-length documents in digital libraries, there is a lack of models offering effective and efficient computational access to these long documents. (2) Nationwide open access services for ETDs generally function at the metadata level. Much important knowledge and scientific data lie hidden in ETDs, and we need better tools to mine the content and facilitate the identification, discovery, and reuse of these important components. (3) A wide range of audiences can potentially benefit from this research, including but not limited to Librarians, Students, Authors, Educators, Researchers, and other interested readers.
Key Research Questions
- How can we effectively identify and extract key parts (chapters, sections, tables, figures, citations), in both born digital and page image formats?
- How can we develop effective automatic classification as well as chapter summarization techniques?
- How can our ETD digital library most effectively serve stakeholders?
Research Areas
In response to the above questions, we plan to compile an ETD corpus consisting of at least 50,000 documents from multiple institutional repositories. We will make the corpus inclusive and diverse, covering a range of degrees (master’s and doctoral), years, graduate programs (STEM and non-STEM), and authors (from HBCUs and non-HBCUs). Testing first with this sample, we will investigate three major research areas (RAs), outlined below.
RA 1: Document analysis and extraction,in which we experiment with machine/deep learning models for effective ETD segmentation and subsequent information extraction. Anticipated results of this research include new software tools that can be used and adapted by libraries for automatic extraction of structural metadata and document components (chapters, sections, figures, tables, citations, bibliographies) from ETDs — applied to both page image and born digital documents.
RA 2: Adding value,in which we investigate techniques and build machine/deep learning models to automatically summarize and classify ETD chapters. Anticipated results of this research include software implementations of a chapter-level text summarizer that generates paragraph-length summaries of ETD chapters, and a multi-label classifier that assigns subject categories to ETD chapters. Our aim is to develop software that can be adapted or replicated by libraries to add value to their existing ETD services.
RA 3: User services,in which we study users to identify and understand their information needs and information seeking behaviors, so that we may establish corresponding requirements for user interface and service components most useful for interacting with ETD content. Basing our design decisions on empirical evidence obtained from user analysis, we will construct a prototype system to demonstrate how these components can improve the user experience with ETD collections, and ultimately increase the capacity of libraries to provide access to ETDs and other long-form document content.
Our research aims to bear cutting-edge computer science and machine/deep learning technologies to advance discovery, use, and potential for reuse of the knowledge hidden in the text of books and book-length documents. In addition, by focusing on libraries’ ETD collections (where legal restrictions from book publishers generally are not applicable), our research will open this rich corpus of graduate research and scholarship, leverage ETDs to advance further research and education, and allow libraries to achieve greater impact.